


There has been a growing interest recently in developing automatic speech recognition (ASR) for under-resourced languages. In our previous article, it was established that in societies with a steady internet connection, social media is popular for voicing views and concerns on social issues. However, in a series of surveys by the United Nations (UN), it was found that radio phone-in talk shows become the medium of choice for such communication when internet connectivity is insufficient or inaccessible. For this reason, the development of radio browsing systems has been piloted with the UN. The Department of Electrical and Electronic Engineering at Stellenbosch University successfully built an automatic speech recognition system for Somali, an under-resourced language. This system monitors such radio shows to obtain information that can inform and support relief and developmental programmes.
The success of the Ugandan system led to the development of a similar system for humanitarian work in Somalia. Since the Somali system was required urgently, it only allowed for the compilation of a 1.57-hour annotated speech corpus. This is very small, even in comparison with the between 6 and 9 hours of data that was gathered per Ugandan language. In addition, linguistic expertise was challenging to find. This article briefly summarises the Department’s efforts to produce the best possible Somali ASR system using this extremely limited speech corpus and to ultimately incorporate it in a radio browsing system for the monitoring of UN humanitarian operations in Somalia.
1. Background
Due to the exceedingly small corpus, the research attempted to capitalise as much as possible on available data from other languages, such as those compiled for the Ugandan radio browsing system, by harnessing multilingual acoustic model training strategies. To achieve this, recent architectures, including feed-forward deep neural networks (DNNs) and time-delay neural networks (TDNNs), were considered. Prior to this work, only a single account of ASR for Somali in the literature has been located. These authors trained a Somali HMM-GMM acoustic model by adapting a French acoustic model using phoneme mapping. A training corpus consisting of 9.5 hours of prepared Somali speech was used. Text normalisation was done using tools prepared in-house to take care of the text variations. Hence, in contrast to the limited speech corpus, they had a well-built Somali corpus, but unfortunately this data was not available to others.
2. Radio browsing system
The structure of the existing radio browsing system is shown below:
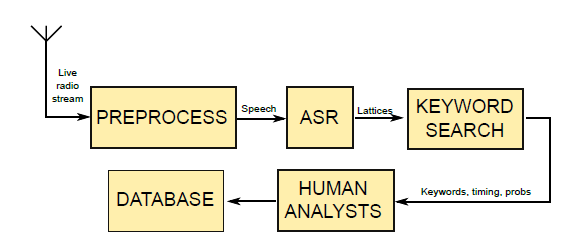
The live audio stream is first pre-processed and then passed on to an ASR system where lattices are generated. These lattices are then searched for specific keywords and the output passed on to analysts for processing. In other words, the same process as is currently being used for the Ugandan languages.
3. Data, acoustic modelling and results
The acoustic training and test data used in the experiments consisted of 1.57 hours of Somali training data and 10 minutes of test data. In addition, 6, 9.6 and 9.2 hours of recorded and annotated radio broadcasts respectively in Ugandan English, Luganda, and Acholi, as well as 20 hours of South African speech recorded from a popular broadcast news channel were available. Furthermore, a South African dataset of code-switched speech including the language pairs English-isiZulu, English-isiXhosa, English-Setswana and English-Sesotho were used consisting of 14.3 hours of spontaneous speech obtained from broadcast soap opera episodes. All these additional datasets were transcribed by native speakers using the standard spelling system of each target language. In addition, pronunciation dictionaries were available to complement the transcriptions.
The Kaldi speech recognition toolkit was used for all experiments. This decoder is based on finite-state transducers and incorporates the language model, the pronunciation dictionary (lexicon) and context-dependency into a single decoding graph. Acoustic models were built using hidden Markov model/Gaussian mixture model (HMM/GMM), subspace Gaussian mixture model, deep neural network (DNN), multilingual DNN, long short-term memory neural network (LSTM), bidirectional LSTM and time delay neural network architectures.
The Kaldi ’wsj’ recipe was modified for the current corpus. Baseline monolingual acoustic models were built using only the Somali data. Then, multilingual models were trained by incorporating the additional languages English, Luganda, Acholi, English-isiZulu, English-isiXhosa, English-Setswana and English-Sesotho. System performance was subsequently reported in terms of word error rate (WER). The table below shows the WERs achieved using various acoustic models. Decoding was performed using language models built with and without artificially generated text to augment the very small language modelling training set. From the table, it appears as if the artificially generated text marginally degrades the performance for the HMM/GMM and SGMM architectures. In contrast, the incorporation of the artificially generated text in the language model results in small improvements for the neural networks acoustic models. The parameters used for LSTM text generation were not optimised and further improvements may be possible.
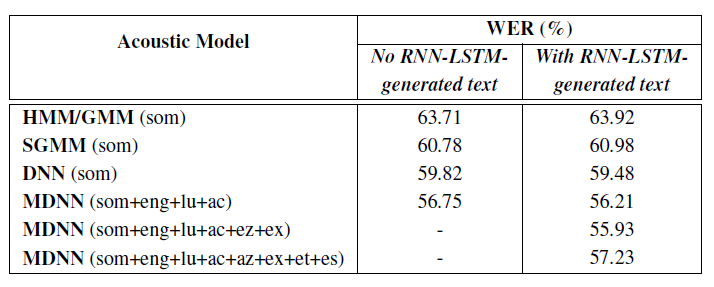
Somali word error rates (WER) achieved using different acoustic modelling methods and different training data.
4. Conclusion
The first efforts in building an automatic speech recognition system for Somali was presented as part of a United Nations programme aimed at humanitarian monitoring. Optimal performance was achieved by a multilingually-trained convolutional neural network – time delay neural network – bidirectional long short-term memory neural network (CNN-TDNN-BLSTM) acoustic model, achieving a word error rate of 53.75%. Augmenting the language model training data using a generative LSTM afforded small gains. The research also found that BLSTM layers consistently benefited more from subsequent adaptation to the target language than LSTM layers.
The final version of the paper this article is based on, has been published at:
Menon R, Biswas A, Saeb A, Quinn J, Niesler T. 2018. Automatic Speech Recognition for Humanitarian Applications in Somali. Available at http://arxiv.org/abs/1807.08669.