


Children can learn new words and corresponding visual objects from only a few word-object example pairs. This raises the question of whether multimodal speech-vision systems can be found that can learn as rapidly from only a few example pairs.
Leanne Nortje is a DeepMind scholar and a PhD student in Electrical and Electronic Engineering at Stellenbosch University. Her research investigates the usage of vision as a form of transcribing speech in a low-resource language. With this research, Leanne hopes also to glean some cognitive insights into how children learn.
She completed her master’s degree under supervision of Dr Herman Kamper, also at the Department of Electrical and Electronic Engineering. Her master’s topic focused on multimodal few-shot learning: to get speech-vision models to learn rapidly from only a few examples.
Background
Imagine an agent like a household robot is shown an image along with a spoken word describing the object in the image, e.g., teddy, monkey and dog. After observing a single paired example per class, it is shown a new set of unseen pictures and asked to pick the “teddy”. This problem is referred to as multimodal one-shot matching. If more than one paired speech-image example is given per concept type, it is called multimodal few-shot matching. In both cases, the set of initial paired examples is referred to as the support set.
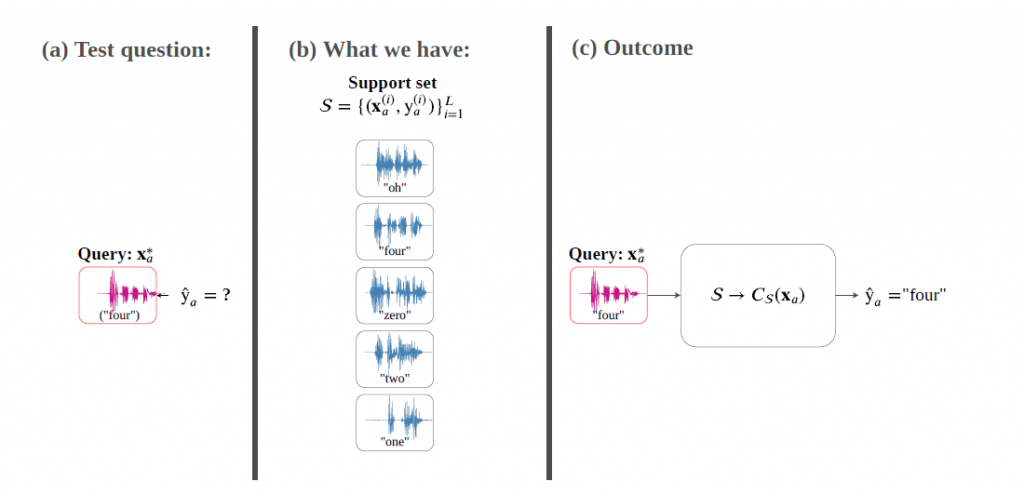
Contribution of the research
The research discussed here makes two core contributions. Firstly, it compares unsupervised learning to transfer learning for an indirect multimodal few-shot matching approach on a dataset of paired isolated spoken and visual digits. Transfer learning involves training models on labelled background data not containing any of the few-shot classes; it is conceivable that children use previously gained knowledge to learn new concepts.
It is also conceivable that before seeing the few-shot pairs, a household robot or child would be exposed to unlabelled in-domain data from its environment. Leanne’s research therefore considered unsupervised learning for this problem – the first to do this. In unsupervised learning, models are trained on unlabelled in-domain data. From the experiments conducted, the research found that transfer learning outperforms unsupervised learning. Leanne explains it as follows:

“Indirect models consist of two separate unimodal networks with the support set acting as a pivot between the modalities. In contrast, a direct model would learn a single multimodal space in which representations from the two modalities can be directly compared. In my research, I propose two new direct multimodal networks: a multimodal triplet network (MTriplet) which combines two triplet losses, and a multimodal correspondence autoencoder (MCAE) which combines two correspondence autoencoders (CAEs).”
Goals of the research
Both these models require paired speech-image examples for training. Since the support set is not sufficient for this purpose, the research proposed a new pair mining approach in which pairs are constructed automatically from unlabelled in-domain data using the support set as a pivot.
This pair mining approach combines unsupervised and transfer learning since the research used transfer learned unimodal classifiers to extract representations for the unlabelled in-domain data. The research showed that these direct models consistently outperform the indirect models, with the MTriplet as the top performer.
These direct few-shot models show potential towards finding systems that learn from little labelled data while being capable of rapidly connecting data from different modalities.
In light of the above, Leanne will be speaking about visually grounded few-shot work learning in low-resource settings at the Deep Learning IndabaX South Africa and you can read more about here research here: https://scholar.sun.ac.za/server/api/core/bitstreams/c3883b07-a3ec-4548-84a9-aebbfd1d4690/content