


In societies with good internet connectivity, social media is a prevalent communication tool. However, where connectivity is insufficient or absent, radio stations that host phone-in talk shows become a popular way for citizens to share news and communicate challenges. Rural Uganda is an example of this. Our previous article highlighted the United Nations (UN) pilot programme rolled out in this area: a radio browsing system that monitors radio discussions to obtain information that can inform the UN’s relief and development programmes. However, this system used a corpus of approximately 9 hours’ worth of annotated audio per target language. From an acoustic modelling perspective, this might be considered a small corpus, but it is nevertheless a key obstacle in terms of how quickly the radio browsing system can be deployed in the event of, for example, a crisis.
- The radio browsing system
- Multilingual DNN/HMM acoustic models
- Data collection and transcription
- Keyword spotting system
- Conclusion
The research that informs this article, combines multilingual acoustic modelling with DNNs and semi-supervised learning to develop an acoustic model for the radio browsing system using just 12 minutes of transcribed speech in the target language. It also defines the role of filters and human analysts as a final component of the radio browsing system which has been key to its active deployment. The focus is specifically on Uganda but is in principle applicable to any under-developed language.
1. The radio browsing system
The radio browsing system currently in use includes an automatic speech recognition (ASR) system configured as a keyword spotter (KWS). It detects segments of normal speech from live audio and excludes non-speech such as music or singing as part of pre-processing. The ASR system processes the selected utterances, and the resulting transcriptions are then searched for keywords of interest. As mentioned in our previous article, this output is passed to human analysts to filter and collect structured, categorised and searchable information suitable for humanitarian decision making and situational awareness.
2.
To address a scarcity of training data in an under-resourced target language, multilingual DNN/HMM acoustic models have been proposed. The DNN is trained with a relatively large training corpus from multiple languages to provide the class conditional posterior probabilities required by HMMs. In this architecture, the DNN shares hidden layers across all languages, but each language has its own softmax layer and HMM.
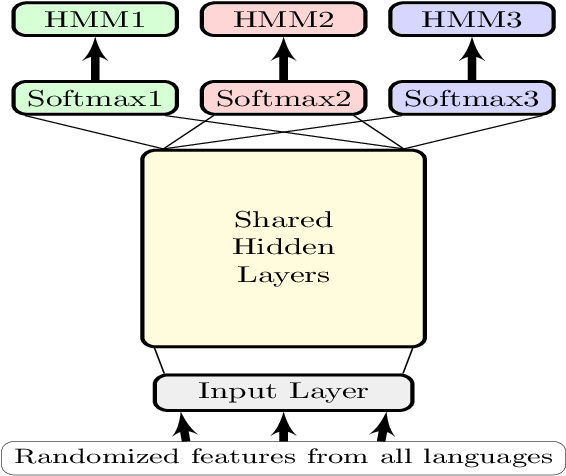
3.
The datasets used in this research were obtained from radio broadcasts recorded in Ugandan English, Luganda and Acholi and transcribed by mother-tongue speakers. Although internet penetration in Uganda is low, mobile phones are abundant and have made radio a vibrant medium for interactive public discussion. Vulnerable groups make use of phone-in or text-in radio talk shows to discuss issues related to, for example, agriculture, health, governance and gender. Corpora were compiled and used to develop a radio-browsing system for Ugandan English and two indigenous African languages, Luganda and Acholi. The systems employ ASRs by using HMM/GMM, SGMM and DNN/HMM acoustic models as keyword spotters.
4.
Keyword spotting can be performed in numerous ways, and one can broadly discern between supervised and unsupervised approaches. Among supervised approaches, one can further distinguish between approaches based on acoustic keyword models, large vocabulary continuous speech recognition (LVCSR), sub-word models, and query-by-example . The Ugandan keyword spotting system used LVCSR to produce lattices, which are subsequently indexed and searched. Since the database that is being used is highly accented, under-resourced and under-represented, it is assumed that all the search words are known in advance. In this way, the additional challenges of effectively dealing with out-of-vocabulary (OOV) words were avoided. Unsurprisingly, systems that were trained on all 9 hours of manually transcribed data, achieved the best keyword-spotting performance.
5.
Recurrent anecdotal evidence suggests that local African radio broadcasts often contain relevant, actionable information that can be used to guide relief programmes. This information is in advance of national-level reporting while also falling below the threshold for publication. This research reports on the first steps of developing a system that can automatically extract such information from radio broadcasts, to pass it to programme managers for verification and action. The radio-browsing system was developed in three languages: Ugandan English, Luganda and Acholiand is the first time that speech recognition systems have been developed for the latter two. Four different speech recognition architectures and system combinations were considered. It was found that the best individual system performance was achieved by a DNN/HMM architecture but that further improvements were possible with system combination. Ultimately, the purpose of the system is to provide. The performance of the radio-browsing system has proved to be sufficient for real-world application and is currently actively deployed in Uganda, providing managers of relief and development programmes at the United Nations with current information to inform their decisions.
The final versions of the papers this article is based on, have been published at:
- Menon, R., Saeb, A., Cameron, H., Kibira, W., Quinn J. and Niesler, T. Radio-browsing for developmental monitoring in Uganda, 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2017, pp. 5795-5799, doi: 10.1109/ICASSP.2017.7953267.
- Saeb, A., Menon, R., Cameron, H., Kibira, W., Quinn, J., & Niesler, T. (2017). Very Low Resource Radio Browsing for Agile Developmental and Humanitarian Monitoring. Interspeech (2017). Available at https://www.semanticscholar.org/paper/Very-Low-Resource-Radio-Browsing-for-Agile-and-Saeb-Menon/1e35d982f3bbb1bbd8e2a56a701803d76bfaff04.